Sample Similarity Search
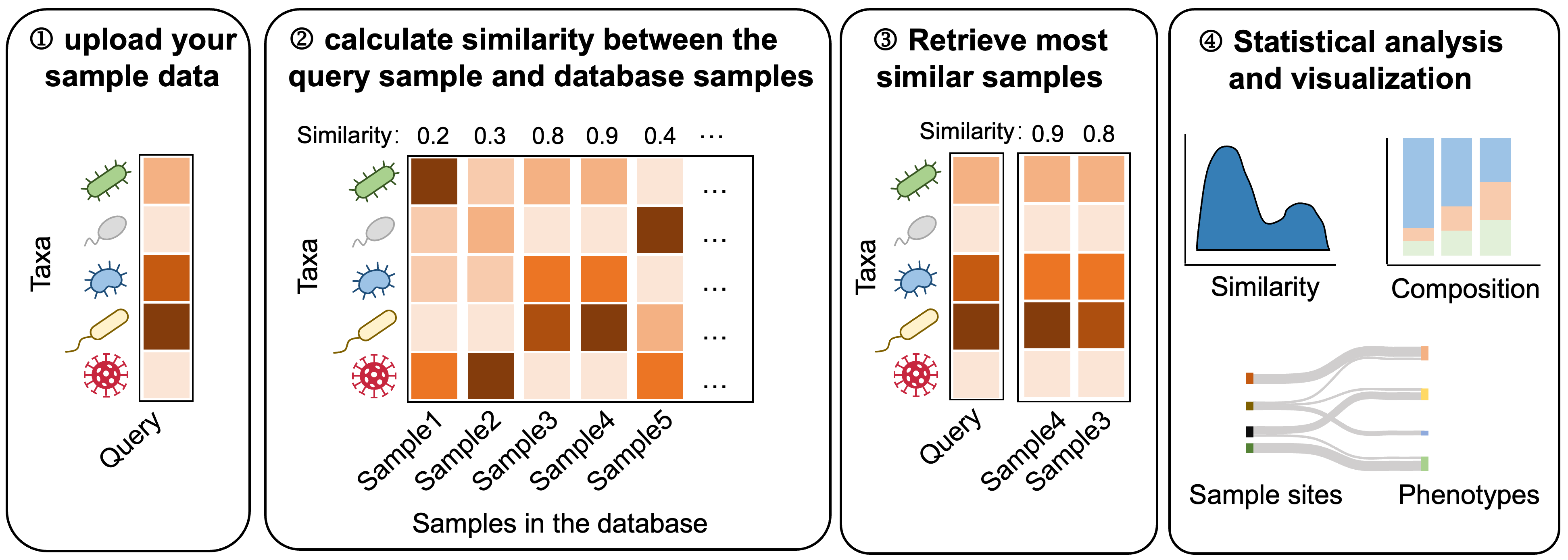
Sample Similarity Search identifies the most similar samples in the database based on a user's query. It provides integrated statistical analyses and visualizations using downloadable metadata and microbial composition data.
This tool enables users to evaluate whether their sample deviates from a healthy respiratory microbiome baseline or to determine which disease conditions or sample sites it most closely resembles. Therefore, it supports early detection of microbial deviations associated with disease onset, facilitates monitoring of microbiome dynamics during treatment or recovery, and aids in identifying atypical or emerging respiratory infections.